Spoiler Alert – Nimble All Flash Array creates great user experience with Citrix and MCS.
Overview:
We purchased a Nimble CS460 X2 for our environment about 3.5 years ago. The CS460 is effectively a Hybrid Array although nimble calls it an Adaptive Flash Array… I guess because they think their caching algorithm is too good to use the term Hybrid. Since the initial purchase we have grown tremendously and done a few upgrades, specifically a cache(SSD) upgraded and 2 capacity shelves(spinning disk with some SSD). At the time of the initial purchase we were running about 100 VM’s comprised of 1000 Exchange Mailboxes and 300 users across 10 xenapp servers. Now our environment is over 350 VM’s comprised of 2500 Exchange Mailboxes and close to 1000 xenapp users across 60 xenapp servers not to mention numerous ancillary services. The nimble CS460 has treated us well and met the demands of any workloads we could throw at it. However, when a system reaches 3.5 years of age there is a depreciation problem that happens when you want to add something like a capacity shelf and that is that it needs to be depreciated over the useful life…. which in the SAN world is associated with the useful life of the head. Because of this it is often cheaper or at least reasonable, as a service provider, to purchase a new head that can be amortized over a longer period of time than add an expansion to systems over 3 years old. We decided to investigate the possibility of a new system and of course all flash arrays being all the rage made us look at nimble AF1000, AF3000, AF5000 product line. Ultimately we decided to test drive the AF5000.
The concept we explored was to keep the nimble CS460, i.e. hyrbrid, for our higher capacity(GB) stuff. This means file servers, exchange servers and even database servers. Then we would take our xenapp servers that should be highly de-duplicate-able and move them to the all flash array. Xenapp performance drives user experience and operational efficiencies. For operational efficiencies think patching, updating, machine creation services and provisioning. We reasoned that if sufficiently high deduplication rates exist then we might be able to cost justify the extra expense of all flash. We also want to determine if the all flash makes a difference on the latencies experienced by the xenapp servers and if qualitatively we thought it made better user experience. The third item we were interested in exploring is any operational improvements related to Machine Creation Services(MCS) and patching.
To summarize our criteria for being able to justify all flash over a new hybrid is
High Enough Deduplication Rates to drive down $ per GB
Measurable reduction in latency and latency spikes for xenapp
Qualitative Improvements to User Experience – We recognize that being “snappier” is hard to gauge.
Measurable improvement to Machine Creation Services(MCS) times
Measurable improvements to patching
Other All Flash Options:
We also knew we had other options besides nimble if we were going to be making an major investment in storage. Some of the options and reasons we did not look at them were
- MCS IO Optimization– This was made available with XenDesktop 7.9 – We didn’t go this route because we didn’t like the idea of an extra layer being added to our environment, i.e. specific configurations of the Machine Catalog and VDA Agent and having to manage user to memory ratios. In general we want to keep things as simple as possible. We also have some xenapp 6.5 servers still around and this doesn’t provide any benefit to those. Another con to the MC IO Optimization is that if we have non xenapp workloads that we want to give the top shelf performance to we wouldn’t be able to.
- Other All Flash Array Vendors – We have some experience with these players but the fact that we could use Nimble Replication from the All Flash Array to the lower cost Hybrid in our second datacenter makes the economics favor staying with nimble.
- Server Side Caching Solutions – This type of solutions uses local ssd or memory in the hosts to give performance improvements to the guest. In looking at these solutions we did not like how they have to integrate with the hypervisor and did not like the idea of adding hardware to the servers. It is cool in concept but we felt that it didn’t actually simplify things and is too immature at this point in time.
Direct Comparison with Other Vendors:
I have been asked by some to do a comparison of Pure Storage All Flash vs Nimble AFA or Nimble vs Netapp FAS AFA but it is extremely difficult if not impossible to compare with synthetic workloads. Most of our data comes from real world work loads and we write about our experiences moving production environments to these solutions rather than compare with theoretical test. Unless Pure Storage or Netapp is willing to give us a box for 120 days at no cost then we can’t accurately compare real world workloads on these systems. If you are looking for an architecture comparison of various AFA manufactures there are plenty of other writers on the web that have blogged on the architecture of Pure Storage or Nimble AFA. I will say that we have worked with and installed other vendor AFA products for customers and they are also good products we just don’t have the level of insight in to those environments to write about them.
What did we want that Nimble AFA couldn’t provide:
- We love the concept to of “managing vm’s not LUNs” and have experience some of the LUN management challenges hinted at by the slogan. Nimble doesn’t currently deliver this and is ultimately is a LUN based system that tries to mask this with some vmware vsphere plugs. However rather than invest in a proprietary VM Management paradigm we are really hoping vvols solves this issue for the market at large and decided against looking at other options.
- Nimble can’t provide all flash for my entire environment at an affordable price.
- Nimble “sort of gets” citrix but doesn’t have much data published regarding All Flash Arrays and Citrix. Questions like should i use PVS or MCS with Nimble AFA…how many users does it scale to…what kind of dedup rates can I expect?
Technical Overview of our Environment:
- We are running 2 x HP Blade Systems and 1 Super Micro Twin2. In total we have 25 Servers running VMware and 2 Servers running Hyper-V.
- Our CS460 Hybrid has ~80TB post-compression.
- We have about 350 VM’s the large majority of which are Microsoft.
- We are supporting about 1000 Xenapp users and 2500 Exchange Mailboxes
- We have about 40 File Servers and the rest of the servers are app and database servers
- We run iSCSI not FC
Deduplication Rates with Nimble All Flash Array
The capacity for all our xenapp servers was estimated to be 15TB pre data reduction. You can see from the screenshot below that we are getting a little over 3 X deduplication and 1.5 X compression. Nimble calls this a 4.5 X savings.


If you look at our volumes, pictured above(which doesn’t show deduplication), you can see an important point when it comes to our Citrix environment. We are running a mix of Xenapp 6.5 servers and 7.11 servers. Because of this mix it is difficult to determine which environment the de-duplication savings are coming from, i.e. does our Xenapp 6.5 environment dedup better or worse than our Xenapp 7.11?
The 6.5 environment is what I call “static servers with users pinned”. This environment doesn’t take advantage of profile management or image management tools. This environment has heavy profile bloat and its not clear to me if user profiles dedup well or not.
The 7.11 environment is using machine creation servers or MCS as the Citrix geeks call it. This environment has a gold image volume that contains a number of gold images where each customer has one gold image. Then it contains the volumes that machine creation services builds its machine catalogs on using the gold image as a source. With this environment we reason that deduplication comes in a few forms; 1) all the gold images should be very similar except for a few apps hence dedup very well, 2) Then the “base” image created from the gold image with machine creation services should dedupe very well since it is a 1 for 1 copy of the gold image. 3.) the “identify disk” and “difference disk” will be fairly unique unless users have very similar profiles. Because this environment is in its infancy and it is on the same array as the 6.5 environment it is hard to understand what the deduplication rates for each environment are. We can however theorize on what we expect which is rehashed below
Gold/Master Images – High DeDup Rates and grows with the number of customers provided they are using the same template and OS. I should point out that in an enterprise you want as few Gold Images as possible, however in a “Multi-Tenant” environment you may have Gold’s for each tenant and hence get much better DeDup.
Base Images – Extremely High DeDup because each Base is a 1 to 1 with the Gold.
Difference Disk – Unknown – This is where the user profile gets “sucked” in with Citrix UPM and other data is written until the machine is rebooted.
There is a great article that talks about the gold image model to help you understand what is happening behind the scenes. https://www.citrix.com/blogs/2014/03/10/xendesktop-mcs-vs-view-composer/
Latency from the Array’s POV
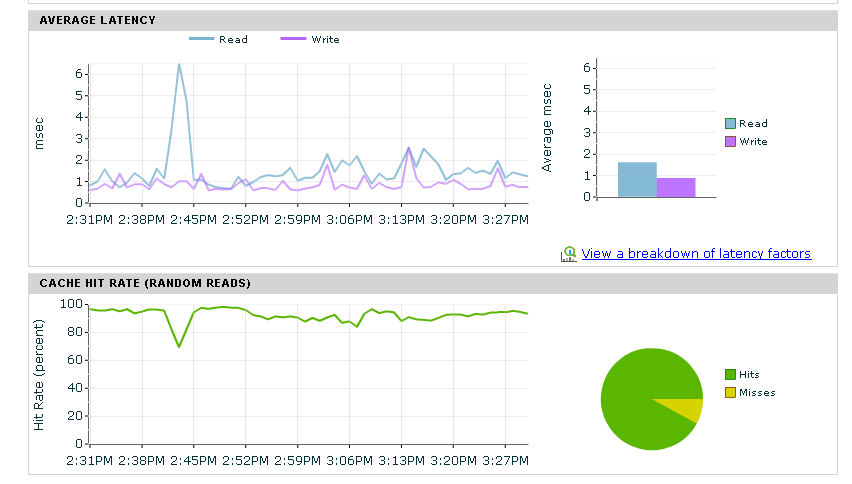
The AF5000 delivers on the low latency promise. When it comes to latency you need to look at the various layers of your stack with the most important being the latency that the guest itself is getting. But to as a first step we will look at the array’s vantage point which measures from when the IO request hits the nimble to when it acknowledges to write or responses with the block requested by the read.
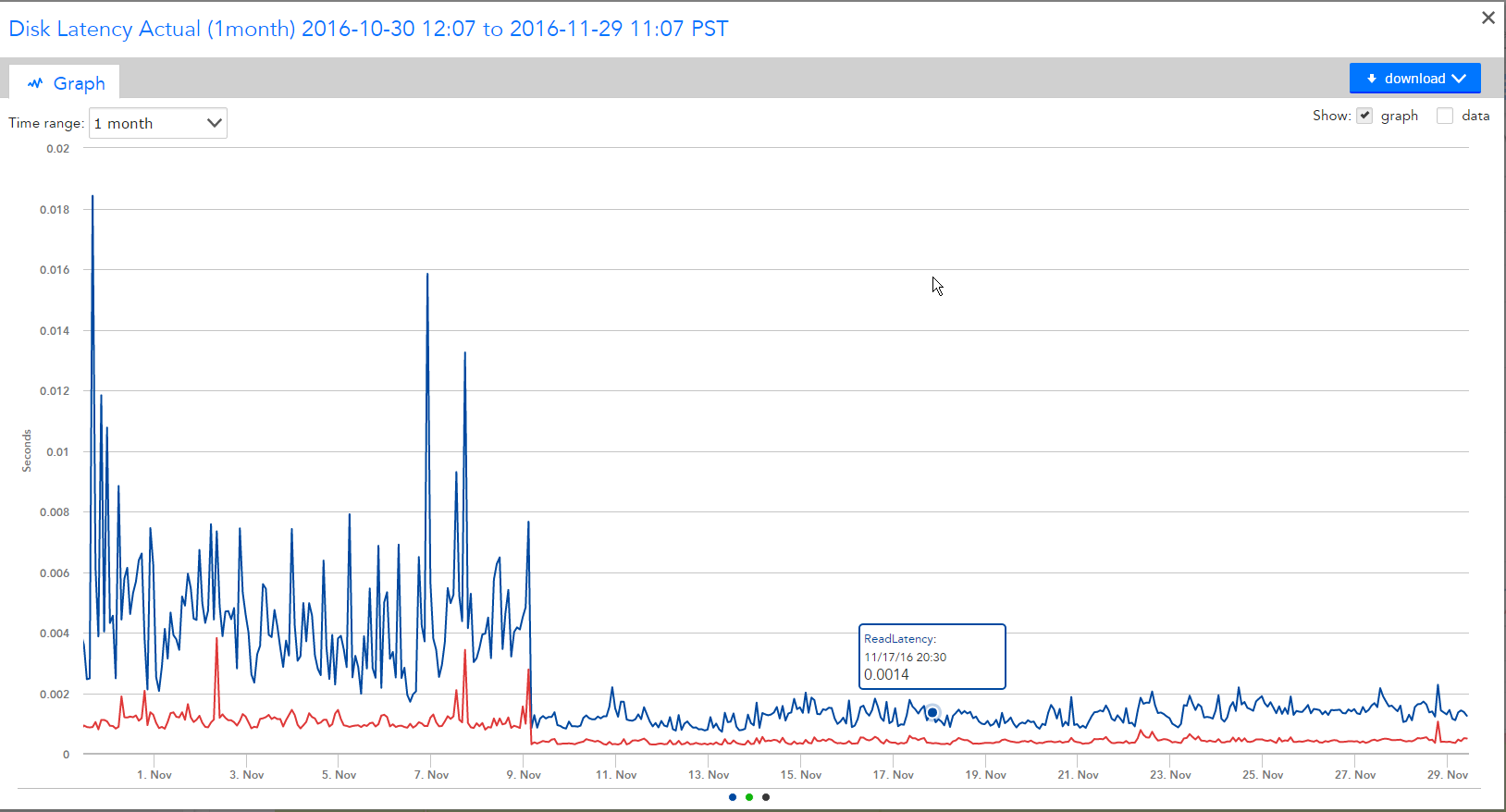
You can see in the picture above that the latency on the All Flash Array stays sub-millisecond for both reads and writes. The only spike is when I was running 10 VM Storage Motions jobs at once(~8:00pm) in which the array is still delivering sub 1ms writes and sub 1.5ms reads. If you don’t know much about storage performance…. this rocks. I didn’t copy the screenshot but the vmstorage motion was sourcing from the Hybrid. The read latency on the hybrid jumped to 40ms during the 10 vstoragemotions and the write latency stayed sub 2ms. The read latency jumped on the hybrid because the vstoragemotion taps the “cold blocks” of the VM that are not in cache and forces the array to read from much slower NL SAS disk.
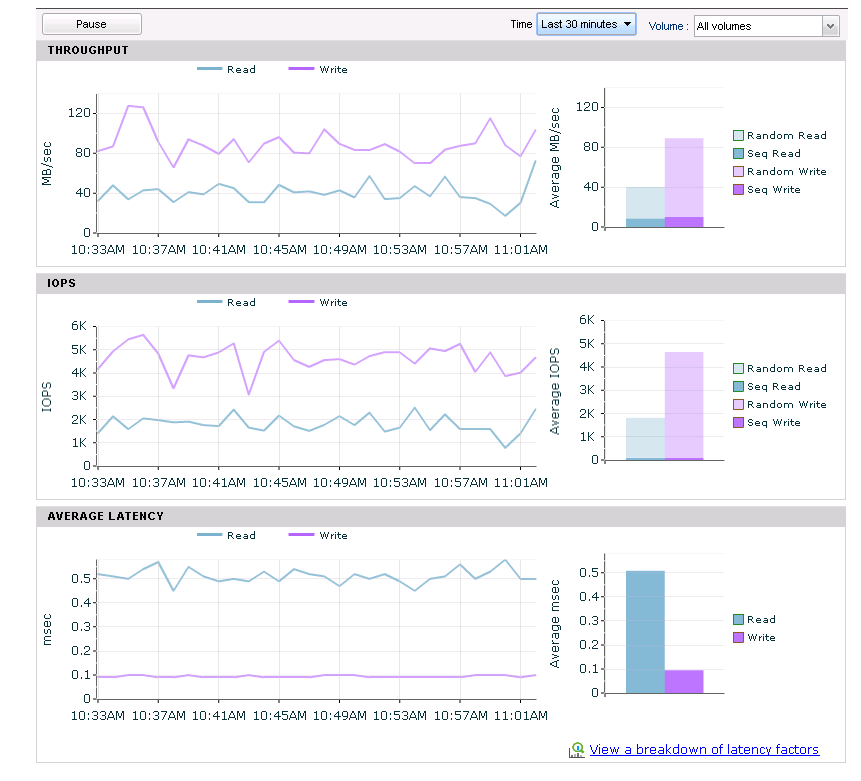
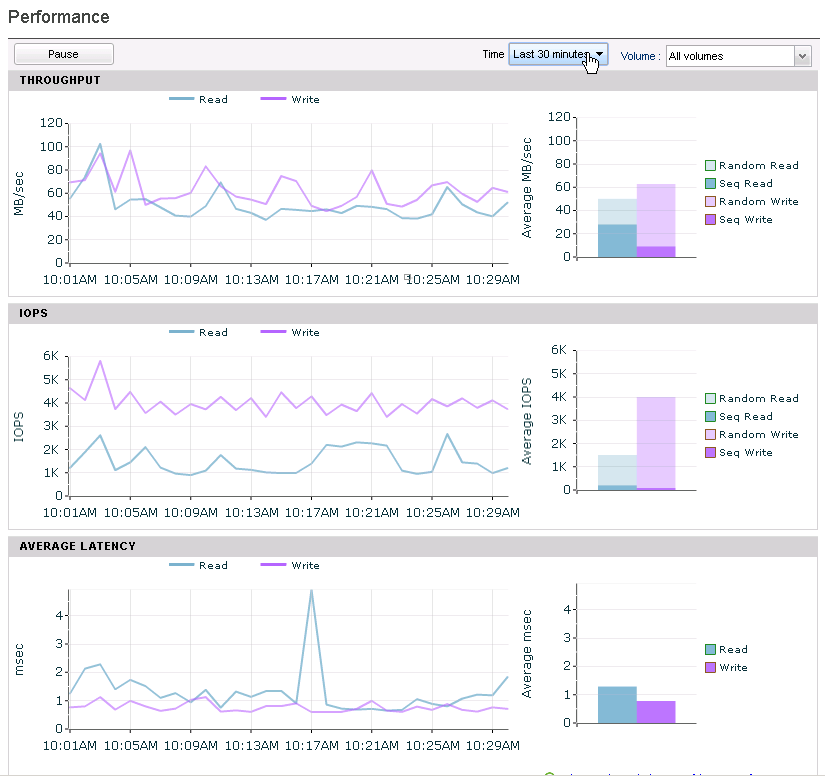
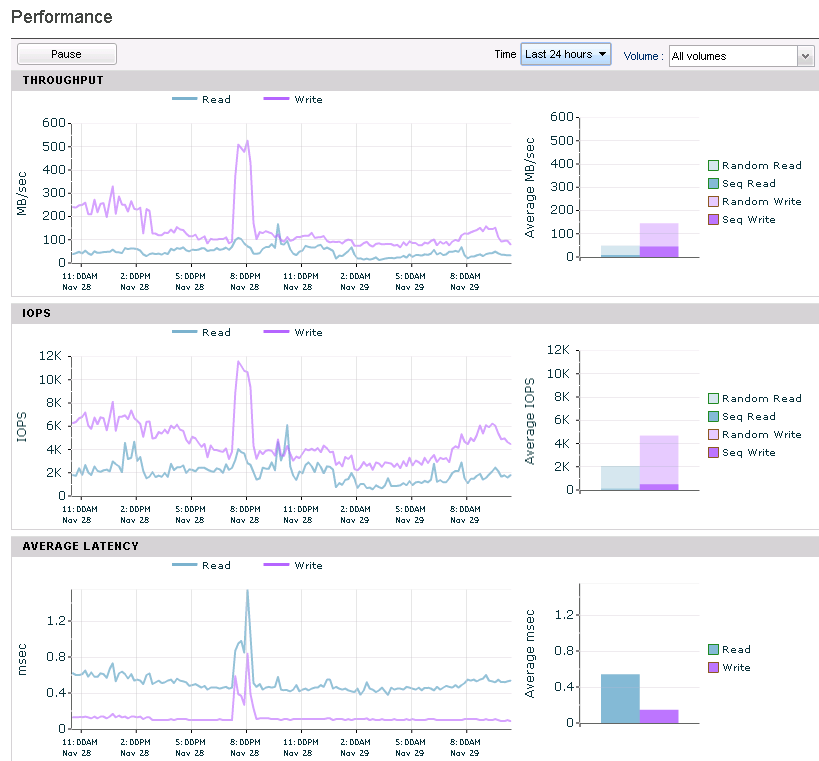
Moving on to a direct comparison between the AF5000 and the Hybrid CS460 you can look at the two screenshots above that show a 30 minute window of each of the array’s performance. In the top picture you can see that the All Flash Nimble Array has write latencies at about .1ms while in the bottom picture the hybrid has write latencies at about .9ms. I believe this difference is actually due to better NVRam in the AF compared to the 3.5 year old NVRam in the Hybrid rather than a result of the all flash design. Looking at the read latencies you can see the All Flash Nimble Array staying very steady at .5ms where as the Hybrid is averaging between 1.5 and 2ms with a spike up to 4ms. This is where the all flash array shines as it always has sub millisecond read latencies whereas the hybrid has mostly low read latencies but spikes with cache misses.
Latency from the Guest
This is very cool and probably the million dollar graph! It is from Logicmonitor and shows a 3 day view of read and write latency from the C Drive of a Xenapp Server. You can see the day we vstoragemotioned the VM(Nov 9th) from the Hybrid to the All Flash that both the read and write latencies dropped. As I stated before I believe that the write latency drop is related to NV Ram not All Flash but the lower and more consistent read latency is 100% related to the All Flash array. Those that are storage buffs will quickly point out that even though the read and write latencies on the Hybrid higher they were still mostly sub millisecond. This observation leads to the most important question when looking at an All Flash Array, does the lower latency improvement positively impact any meaningful aspect of an organizations IT when the current latencies are already good? Said another way, the good news is this graph shows the Nimble All Flash Array(AF5000) delivers on its promise of better and more consistent performance that its hybrid counter part HOWEVER it does not mean that going from good to great warrants the extra investment because it may not add any perceivable value to your organization. Hopefully me outlining our decision making process as it relates to our Citrix environment helps others grasp how they might make such evaluations of All Flash in their own unique environments. I contend that one of the most powerful parts of the Nimble Storage story is to have an All Flash Array Mixed with a Hybrid that is managed as a single unit, allowing you to move some workloads such as Citrix to All Flash and keep others that get no benefit on Hybrid.
Machine Creation Services (AKA MCS)
On the Hybrid CS460 our machine catalog updates(MCS) were taking between 15 and 20 minutes which is acceptable and generally considered good performance in the MCS world. For those not familiar with MCS and Machine Catalogs this basically means that we update the gold image with patches, software, etc and then need to update the Machine Creation Catalog to push the changes which ready’s them to be applied upon the magic reboot which then gives users the updated desktop. Behind the scenes this process of updating the machine catalog creates a lot of Storage IO and leverages a VM Clone operation. When we moved the Machine Catalog and Gold Images to the Nimble All Flash Array the times for the MCS jobs dropped from 20 minutes to 6 minutes. You can see in the first screenshot below that the MCS job on the AFA took ~6 minutes. The bottom screenshot show a MCS jobs on the Hybrid array that took 17 minutes. This ~3X improvement is pretty consistent across our various Machine Catalogs which tend to have gold images between 40GB and 60GB.


One new VMWare concept that many don’t know about is Xcopy. Xcopy is a VAII primitive to move the burden of copying large files from the host and storage array to just the storage array… think virtual machine cloning type functions which normally need to flow through the NIC/HBA of the host. Nimble implements XCopy but has not yet introduced what I call the “dedup friendly” xcopy. The dedup friendly version is an array specific implementation that allows the array to recognize that since the blocks already exist they don’t need to be read and put through the deduplication engine but rather can just have the deduplication tables updated very quickly. In theory MCS jobs and anything leveraging VM Cloning would takes seconds rather than minutes with a good implementation of DeDup friendly Xcopy implementation. This feature is actively being worked on by Nimble and we are told will be released soon. Xcopy is not without issues right now in the industry as it is not well understood and you are forced to scower the internet for articles here and their to understand it. I found a blog entry by Cody Hosterman that spells out some adjustments you may need to make for Xcopy to work with a VM that is turned on http://www.codyhosterman.com/tag/xcopy/ . I suspect those that get deep into the details and are into getting the most performance out of their Arrays will be learning lots about Xcopy in the coming years as All Flash and DeDup become standard features. With a good implementation of Dedup Friendly Xcopy creating a vm from a template will take seconds! We are hopeful that MCS combined with DeDup friendly Xcopy will lower our MCS times even further.
Patching
We don’t have much data on patching the xenapp servers while on the All Flash Array as we have only had 1 patch window during our tests. The concept is that patching the xenapp servers should be quicker( in terms of human labor) and reboot times fast and consistent with the fixed read latencies provided by the AFA. Even though we don’t have much data yet we do have an idea of what to expect and these improvements are different for the xenapp 6.5 environment vs the Xenapp 7.11 with MCS.
With our Xenapp 6.5 environment patching is done during a weekly maintenance window and needs to be done quickly before the window closes. This was fine at small scale but as our environment and number of xenapp servers grew it quickly become a highly skilled job that allows for little margin of error. In addition, IMA service crashes or other issues need to be caught by a post patch login check on each server. We are hopeful that the All Flash array should reduce the time to install the patches by at least 50%(based on MCS reduction times) and reduce the time to reboot.
With MCS in our Xenapp 7.11 environment patches are done during the day to the gold image. Then the gold image is used to update the Machine Catalog which primes the environment but has no impact on the end users until a special reboot command is issued at our leisure. The operational improvement we are expecting with the All Flash and the 7.11 environment is the ability to patch and update machine catalogs for our 40+ Gold Images in the day with 0 impact to production. We do not believe this would be possible to do at scale on the hybrid array, i.e. 40 gold images and MCS Update jobs in an 8 hour day, without some level of impact to the customer. For us, this ability to handle Machine Creation Service Functions during the day without impact to other customers is one of the most compelling reasons to move to an All Flash Array for Citrix.
Other Items of Note
Snapshots – After we moved the Xenapp Servers out of “general customer” volumes to Xenapp specific volumes the amount of space a snapshot takes up is dramatically reduce. We found that our xenapp servers take up the most amount of snapshot space especially if you have 4 hour snapshots. Because of this we get more space back in the Hybrid Array when we move the Xenapp servers off and hopefully less data to send over the wire to the partner Nimble Hybrid. To be fair this is more a product of LUN design than a benefit from the All Flash Array but I thought it was a point worth mentioning.
QoS? – The AFA5000 appears to be able to limit itself from being crushed. The hybrid array had a similar feature but a well design sequential read workload could force it to provide high read latency. With the AFA5000 the latency doesn’t seem to change if we put 5 VStorage Motions or 20. The IOPS stay the same and throughput stays the same so it will take longer to complete all the jobs but the array won’t fall over and will continue to deliver very low latencies. I am sure the disk queue builds up on the HIGH IO request-or side but the other workloads seem to remain relatively unaffected. I see this as a primitive form of QoS as it prevents IO Hogs from getting an unfair share of IO.
User Experience
This is the most important part of our test and is the hardest to measure. We are basically faced with the financial decision to decide if we buy All Flash with proven lower latencies but speculative user experience improvements. When is say speculative I mean that the general feeling by our internal users is that desktops feel faster and snappier. However it is not easy to measure. Adding difficulty in measuring is that in the time we have been testing the All Flash Array we have brought on new customers, moved some customers from Xenapp 6.5 to 7.11, upgraded the OS from Windows 7 Like to Windows 10 Like and added Citrix Workspace Environment Manager(WEM) to our environment. Modifying all of these variables makes quantifying an improvement difficult. Ultimately we decided that the user experience is better and most importantly more consistent even though we can’t measure it. We framed the problem to justify our decision by saying that it is our job is to control all the technical aspects of the system that yield a good desktop experience in a dynamic and rapidly changing environment…storage performance happens to be a key component. So to summarize we THINK but can’t prove we are getting a much better user experience with Citrix on All Flash but we KNOW we are getting a platform that provides operational improvements and can scale with almost zero chance of storage performance being able to impact user experience.
The Law of Averages – Side Note
The law of averages is the dirty little secret of the hybrid world that is the reason All Flash has potential value to some workloads. You can see in the screenshot below that there was a latency spike on our Hybrid Nimble Array. However the spike seems marginal at 6ms read latency, i.e. 6ms is not horrible latency…. however the devil lies in the details. The reality of this event is that even though the average is at 6ms there is a high percentage of reads that were much greater than 6ms. We can do a quick experiment and say that 70% of the reads were cache hits at 1ms so what values do the rest of the 30% of reads have to be to give an average of 6ms. There are many right answers to this problem and one of right answer is that the 30% of reads are actually 20ms, see the second screenshot that summarizes this math.
So the 6ms average essentially is super deflated because anything that is a cache hit is 1ms and it pushes down the average. Turns out averages is a horrible way to describe the data when a cache hit always produces the lowest possible value. This is why an All Flash Array can make sense as their are scenarios when the the great averages the hybrid nimble produces impacts your customers and those occurrences simply get averaged out!
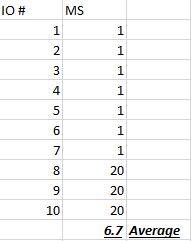
In the real world most general purpose applications don’t have a problem with this behavior and the performance boost they get from most reads being 1ms and all writes to NVRam being sub 1ms makes Hyrbrid a good solution especially given the economics compared to All Flash.
As another side note this law of averages is also the reason that there is a point of diminishing return for having a hybrid with an oversized cache as you reach a point where a lot extra cache only gives a little bit better chance of a cache hit.